R 머신러닝, iris 품종 예측하기

머신러닝을 공부하다 보면 꼭 한번은 만나게 되는 데이터셋이 있습니다.
바로 iris 데이터셋입니다.
오늘은 이 데이터를 가지고 두 가지 분류 모델인 로지스틱 회귀분석과 랜덤포레스트을 적용해 보고,
어떤 모델이 더 정확하게 품종을 예측하는지 비교해보겠습니다.
1. iris 데이터셋
iris 데이터는 꽃받침과 꽃잎의 길이/넓이 정보를 통해 품종(Species)을 예측하는 아주 간단하면서도 효과적인 분류용 데이터입니다.
data(iris)
str(iris)

- 입력 변수 (Feature):
- Sepal.Length, Sepal.Width, Petal.Length, Petal.Width
- 목표 변수 (Target):
- Species → 품종 (setosa / versicolor / virginica)
2. 데이터 시각화 (EDA)
먼저 데이터를 시각화하여 각 품종 간의 차이를 확인해보겠습니다.
library(ggplot2)
ggplot(iris, aes(Petal.Length, Petal.Width, color = Species)) +
geom_point(size = 3) +
theme_minimal()
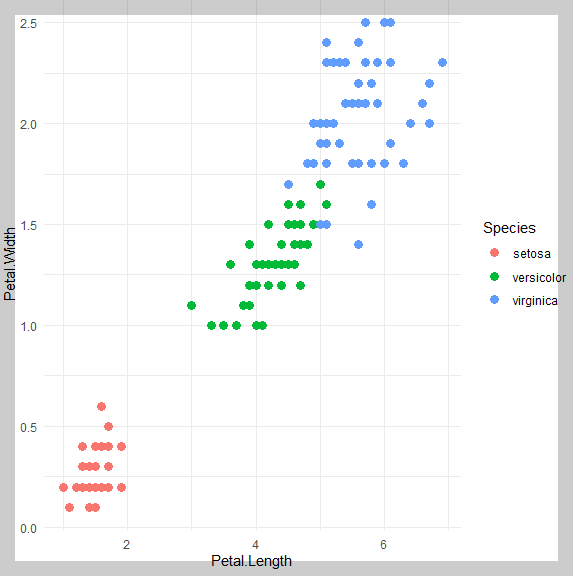
setosa는 다른 품종과 뚜렷하게 구별되는 특성을 보입니다.
반면, versicolor와 virginica는 일부 특성이 겹쳐 있어 예측에 어려움이 있을 수 있습니다.
3. 로지스틱 회귀분석 (Multinomial Logistic Regression)
library(nnet)
model_logit <- multinom(Species ~ ., data = iris)
pred_logit <- predict(model_logit, iris)
library(caret)
confusionMatrix(pred_logit, iris$Species)
혼동 행렬
| 예측\실제 | setosa | versicolor | virginica |
| setosa | 50 | 0 | 0 |
| versicolor | 0 | 47 | 3 |
| virginica | 0 | 1 | 49 |
- 정확도: 146 / 150 = 97.3%
- setosa: 100% 정확도
- versicolor ↔ virginica: 일부 혼동 발생
4. 랜덤포레스트
library(randomForest)
set.seed(123)
model_rf <- randomForest(Species ~ ., data = iris, ntree = 100)
print(model_rf)
pred_rf <- predict(model_rf, iris)
confusionMatrix(pred_rf, iris$Species)
혼동 행렬
| 예측\실제 | setosa | versicolor | virginica |
| setosa | 50 | 0 | 0 |
| versicolor | 0 | 49 | 1 |
| virginica | 0 | 0 | 50 |
- 정확도: 149 / 150 = 99.3%
- 모든 클래스에서 매우 높은 정확도
- virginica 1건만 versicolor로 잘못 분류됨
랜덤포레스트는 여러 개의 결정트리를 결합해 예측 정확도를 향상시킨 모델입니다.
과적합 방지, 변수 중요도 평가 등의 기능이 탁월합니다.
5. 모델 성능 비교
| 로지스틱 회귀분석 | 약 97.3% | 해석이 쉬움, 통계적 의미 부여 가능 | 비선형 문제에 약함, 복잡한 경계 처리 어려움 |
| 랜덤포레스트 | 약 99.3% | 높은 정확도, 변수 간 상호작용 반영 가능 | 해석이 어려움, 느릴 수 있음 |
6. 결론
- 해석력 우선: 로지스틱 회귀 (간단하고 설명하기 좋음)
- 정확도 우선: 랜덤포레스트 (실전 적용이나 자동화 시스템에 적합)
둘 다 훌륭한 성능을 보이지만, 실제 업무나 과제 상황에 따라 모델 선택 기준을 명확히 해야 한다는 점이 가장 큰 시사점입니다.
'IT관련' 카테고리의 다른 글
| 지금 세상을 바꾸고 있는 기술, 생성형 AI란? (0) | 2025.04.24 |
|---|---|
| R로 알아보는 미국 치안지도 ( + USArrests ) (1) | 2025.04.17 |
| R을 활용한 당뇨병 데이터 분류 분석 (0) | 2025.04.16 |
| 수면 시간과 스트레스가 수면의 질에 어떤 영향을 줄까? ( + R 회귀분석 ) (0) | 2025.04.09 |
| 중선형 회귀모델 , 교육, 평판, 여성 비율로 알아보는 연봉 예측 모델 ( +R코드 ) (0) | 2025.04.07 |



