🎥 "영화가 성공하려면 무엇이 필요할까?"
여러분은 영화가 히트하는 데 무엇이 가장 중요한 요소라고 생각하시나요?
막대한 제작비? 유명 배우? 아니면 뛰어난 감독?
이런 궁금증을 데이터로 풀어보는 흥미로운 분석 프로젝트를 준비했습니다!
오늘은 Kaggle에 올라온 영화 메타데이터를 활용해,
영화 성공 요인들을 R로 쉽게 분석하고,
의미 있는 인사이트를 도출하는 과정을 소개할게요.
데이터 분석 초심자분들도 따라하기 쉽도록 차근차근 설명해드릴게요.
📚 사용한 데이터셋 소개
- 데이터명: Movie Industry Dataset
- 출처: Kaggle - Movie Correlation Analysis Dataset
- 내용: 영화의 예산, 수익, IMDb 평점, 감독·배우 인기 지표(페이스북 좋아요 수) 등 다양한 메타데이터
이 데이터셋을 선택한 이유?
→ 다양한 수치형 변수들이 포함되어 있어 상관분석을 하기에 아주 적합합니다.
🎬 Movies Dataset 변수 설명
| name | 영화 제목 (ex. Avengers: Endgame) |
| rating | 영화 등급 (관람가 등급, 예: PG-13, R) |
| genre | 영화 장르 (ex. Action, Drama, Comedy 등) |
| year | 영화 개봉 연도 |
| released | 정확한 개봉일 (월, 일, 연도까지) |
| score | IMDb 평점 (0~10 점수, 소수점 1자리) |
| votes | IMDb에 등록된 투표 수 (관객 리뷰 참여 수) |
| director | 감독 이름 |
| writer | 각본가 이름 |
| star | 주연 배우 이름 |
| country | 제작 국가 |
| budget | 제작 예산 (USD 기준, 숫자형) |
| gross | 전 세계 흥행 수익 (USD 기준, 숫자형) |
| company | 배급사/제작사 이름 |
| runtime | 상영 시간 (분 단위) |
상관분석에 직접 사용할 수 있는 주요 수치형 변수는:
- budget (제작비)
- gross (수익)
- votes (투표 수)
- score (평점)
- runtime (상영시간)
이 5개가 가장 기본입니다.
🛠️ R로 진행하는 상관분석 따라하기
# 필요한 패키지 설치 및 로드
install.packages(c("tidyverse", "corrplot")) # 한 번만 설치하면 됩니다
library(tidyverse)
library(corrplot)
# 1. 데이터 불러오기
# (본인 컴퓨터에 다운받은 movies.csv 파일 경로를 지정하세요)
movies <- read.csv("your_path/movies.csv", stringsAsFactors = FALSE)
# 2. 데이터 구조와 요약 확인
str(movies)
summary(movies)
# 3. 주요 수치형 변수만 선택하고 결측치 제거
movies_numeric <- movies %>%
select(budget, gross, votes, score, runtime) %>%
na.omit()
View(movies_numeric)
# 4. 상관계수 행렬 계산 (피어슨 상관계수)
cor_matrix <- cor(movies_numeric, method = "pearson")
cor_matrix

# 5. 상관관계 시각화 (Heatmap)
corrplot(cor_matrix,
method = "color", # 컬러풀하게
type = "upper", # 위쪽 삼각형만
order = "hclust", # 유사 변수끼리 묶어줌
addCoef.col = "black", # 상관계수 숫자 표시
tl.col = "black", # 변수 이름 색깔
number.cex = 0.7) # 글씨 크기

# 6. gross(수익)와 다른 변수들의 상관계수만 따로 보기
gross_cor <- sort(cor_matrix[,"gross"], decreasing = TRUE)
print(gross_cor)

# 7. 중요한 변수별 산점도(Scatter plot) 그리기
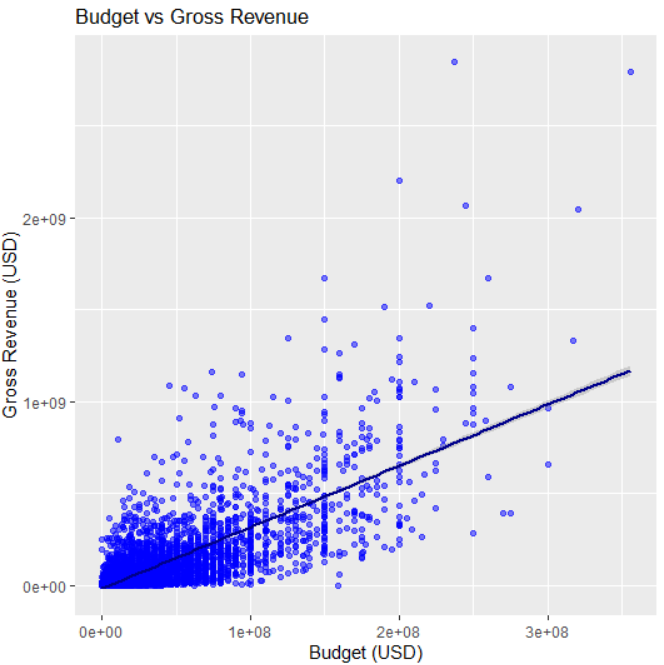
# budget vs gross
ggplot(movies_numeric, aes(x = budget, y = gross)) +
geom_point(alpha = 0.5, color = "blue") +
geom_smooth(method = "lm", col = "darkblue") +
labs(title = "Budget vs Gross Revenue", x = "Budget (USD)", y = "Gross Revenue (USD)")
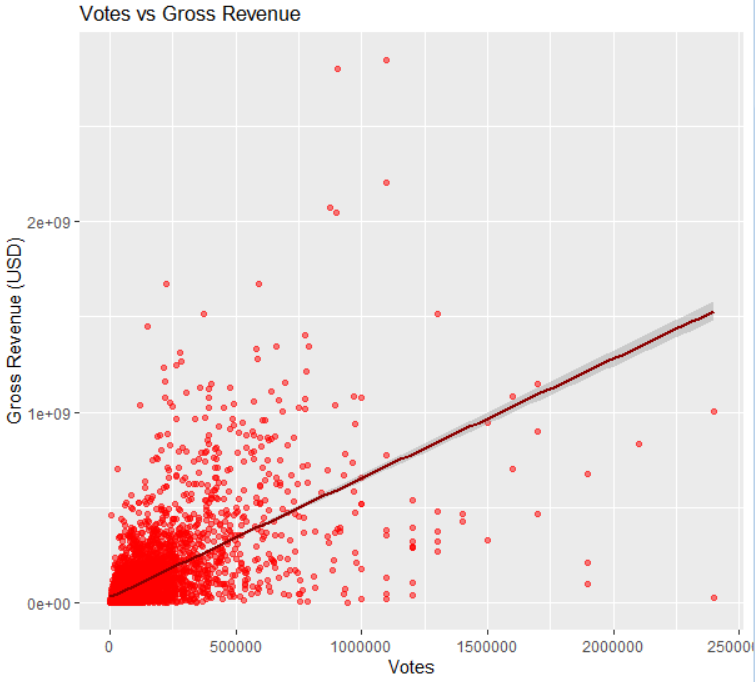
# votes vs gross
ggplot(movies_numeric, aes(x = votes, y = gross)) +
geom_point(alpha = 0.5, color = "red") +
geom_smooth(method = "lm", col = "darkred") +
labs(title = "Votes vs Gross Revenue", x = "Votes", y = "Gross Revenue (USD)")
🔍 분석 결과로 얻은 인사이트
분석해보니 이런 흥미로운 사실들을 알 수 있습니다.
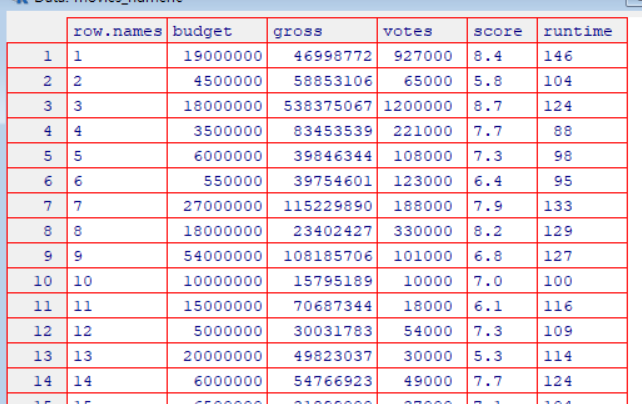
- 🎯 1. budget(제작 예산) → gross(수익)
- 상관계수: 0.74
- 의미: 예산이 많을수록 흥행 수익이 높을 확률이 큽니다.
- 💬 “돈이 많이 들수록, 흥행도 잘된다.” 라는 가설이 데이터에서 뒷받침됩니다.
🎯 2. votes(투표 수) → gross(수익)- 상관계수: 0.61
- 의미: 관객 참여(리뷰/투표)가 많을수록 흥행 수익도 높은 경향이 있습니다.
- 💬 “관심을 많이 받는 영화일수록 흥행한다.” 라는 결론을 내릴 수 있습니다.
🎯 3. runtime(상영 시간) → gross(수익)- 상관계수: 0.2756
- 의미: 약한 상관관계이므로, 상영 시간이 길다고 흥행을 보장하지는 않습니다.
- 💬 약간의 경향은 있지만, 의미 있는 요인으로 보기에는 부족합니다.
🎯 4. score(IMDb 평점) → gross(수익)- 상관계수: 0.2221
- 의미: 관객 평점이 좋다고 해도, 수익과는 큰 상관이 없습니다.
- 💬 “명작이 꼭 흥행작은 아니다.” 라는 사실을 보여주는 흥미로운 지점입니다.
전체 요약하자면
🎬 흥행 수익(gross)에 가장 큰 영향을 주는 요인은
1위: 제작 예산 (budget)
2위: 관객 투표 수 (votes)
반면, 평점이나 상영시간은 상대적으로 영향력이 약한 요인으로 나타났습니다.
결론 : 데이터로 본 영화 성공 공식
이번 프로젝트를 통해 배운 점은 간단하지만 강력합니다.
- 투자는 여전히 결과를 좌우하는 중요한 요소이다.
- 감독과 배우의 인기는 플러스 요인이 될 수 있지만, 영화 성공을 전적으로 보장하지는 않는다.
- 데이터는 숫자 이상을 말해준다. 직관을 데이터로 검증하는 것이 중요하다.
🎬 영화도, 데이터도 결국 사람들의 마음을 움직이는 데서 출발하는 것 아닐까하는 생각이 듭니다.
R코드 다운로드
'IT관련' 카테고리의 다른 글
| 메타 점수가 높은 게임들의 공통점은? ( 캐글 데이터로 보는 게임 공식 ) (0) | 2025.04.30 |
|---|---|
| 직장인을 위한 ChatGPT 꿀팁( + ChatGPT 프롬프트 50선 다운로드) (0) | 2025.04.28 |
| R로 배우는 회귀분석 실습 ( 베이징 미세먼지(PM2.5) 데이터 분석 ) (0) | 2025.04.24 |
| 지금 세상을 바꾸고 있는 기술, 생성형 AI란? (0) | 2025.04.24 |
| R로 알아보는 미국 치안지도 ( + USArrests ) (1) | 2025.04.17 |



