심혈관 질환 예측 보고서 : 혈압과의 관계 분석
Kaggle의 'Cardiovascular Disease Dataset'을 기반으로, 수축기 혈압(ap_hi)과 심혈관 질환(`cardio`) 간의 관계를 중심으로 심혈관 질환 예측 모델을 구축하고 인사이트를 도출해 보겠습니다.
데이터 수집 및 전처리
- 총 샘플 수는 약 70,000건이었습니다.
- 주요 변수는 다음과 같습니다:
- `ap_hi`: 수축기 혈압
- `ap_lo`: 이완기 혈압
- `age`: 일(day) 단위 → `age_years` (연 단위)로 변환
- `cardio`: 심혈관 질환 유무 (0: 없음, 1: 있음)
- 기타: BMI, 성별, 콜레스테롤, 혈당, 흡연, 음주, 활동 여부
1. 패키지 설치 및 로드
packages <- c("tidyverse", "janitor", "pROC", "broom", "ggplot2", "gridExtra", "scales")
install.packages(setdiff(packages, rownames(installed.packages())))
lapply(packages, library, character.only = TRUE)
2. 데이터 불러오기 및 전처리
data <- read_csv("cardio_train.csv",show_col_types = FALSE) #age는 일단위임
View(data)
data <- read_csv("cardio_train.csv") %>%
clean_names() %>%
mutate(
age_years = floor(age / 365),
bmi = weight / ((height / 100)^2),
cardio = factor(cardio)
)
# 이상치 제거 (비현실적인 혈압 수치)
data <- data %>%
filter(ap_hi > 80, ap_hi < 250, ap_lo > 50, ap_lo < 150)
View(data)
str(data)
tibble [68,565 × 15] (S3: tbl_df/tbl/data.frame)

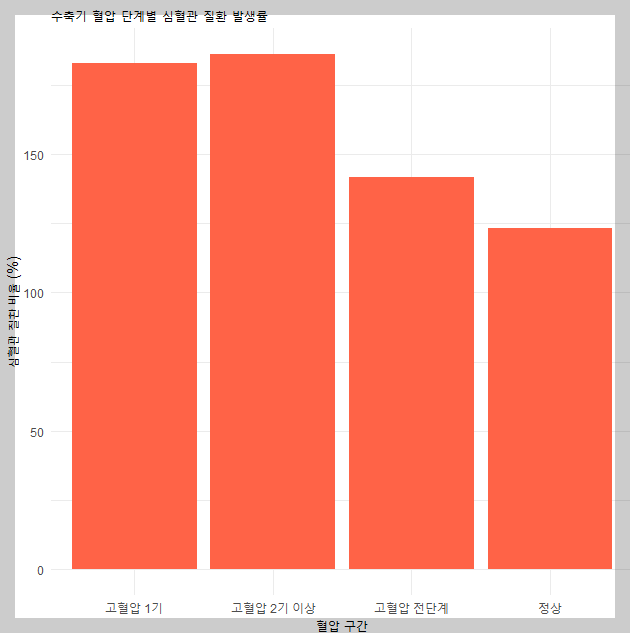
혈압 단계별 질환 비율 시각화
수축기 혈압을 네 단계로 나누고 각 단계별 심혈관 질환 비율을 계산한 결과는 다음과 같았습니다:
| 혈압 단계 | 심혈관 질환 발생률 (%) |
|-------------------------|------------------------|
| 정상 | 23.9% |
| 고혈압 전단계 | 42.3% |
| 고혈압 1기 | 83.1% |
| 고혈압 2기 이상 | 87.3% |
data <- data %>%
mutate(bp_category = case_when(
ap_hi < 120 ~ "정상",
ap_hi < 140 ~ "고혈압 전단계",
ap_hi < 160 ~ "고혈압 1기",
TRUE ~ "고혈압 2기 이상"
))
bp_stats <- data %>%
group_by(bp_category) %>%
summarise(질환비율 = mean(as.numeric(cardio)) * 100)
ggplot(bp_stats, aes(x = bp_category, y = 질환비율)) +
geom_bar(stat = "identity", fill = "tomato") +
labs(title = "수축기 혈압 단계별 심혈관 질환 발생률", x = "혈압 구간", y = "심혈관 질환 비율 (%)") +
theme_minimal()
→ 수축기 혈압이 높을수록 심혈관 질환 발생률이 뚜렷하게 증가했습니다.
로지스틱 회귀분석 및 결과
회귀 모델:
model <- glm(cardio ~ ap_hi + ap_lo + age_years + bmi + gender + cholesterol
+ gluc + smoke + alco + active, data = data, family = "binomial")
summary(model)
# 승산비
odds <- tidy(model, exponentiate = TRUE, conf.int = TRUE) %>%
select(term, estimate, conf.low, conf.high, p.value)
print(odds)
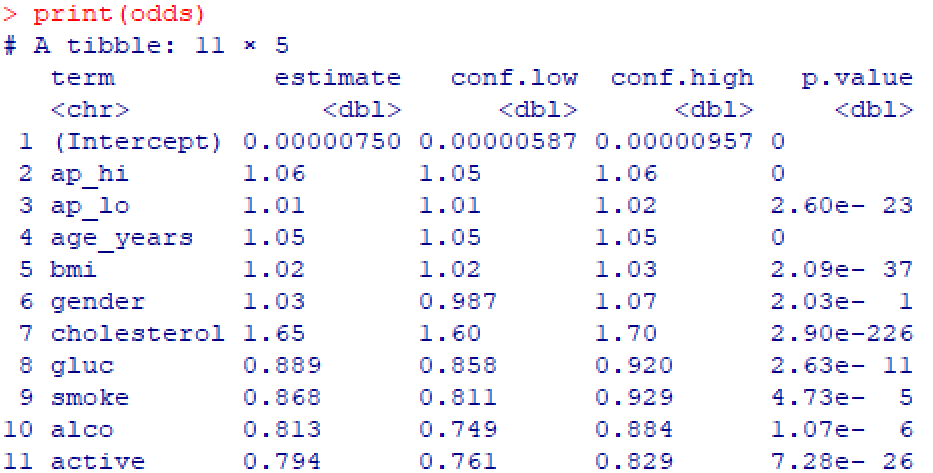
로지스틱 회귀분석 결과 :
- 수축기 혈압이 1단위 증가할 때 위험이 6% 증가
- 이완기 혈압이 증가할수록 위험이 1%씩 증가
- 나이가 한 살 많을수록 위험이 5% 증가
- BMI가 높을수록 위험이 2% 증가
- 유의하지 않음 → 성별은 유의한 영향이 없음
- 콜레스테롤이 높을수록 위험이 65% 증가
- 혈당 수치가 높을수록 위험이 감소하는 결과
- 흡연자가 오히려 낮은 위험을 보임
- 음주자도 위험이 낮게 나타남
- 활동적인 사람은 질환 위험이 21% 감소
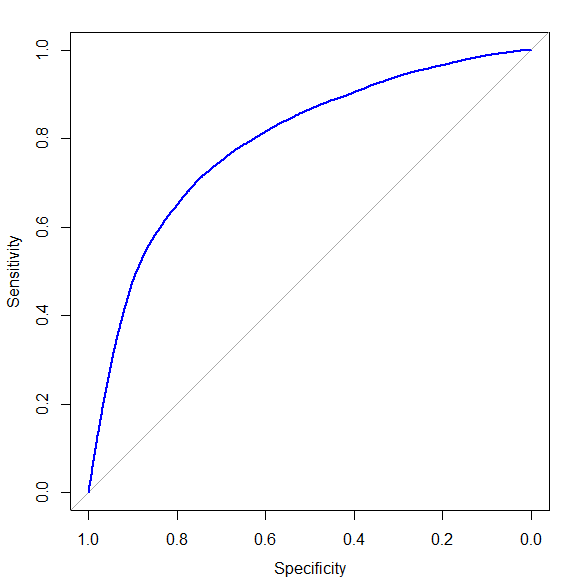
모델 평가: 정확도 및 AUC
data$pred <- predict(model, type = "response")
roc_obj <- roc(data$cardio, data$pred)
plot(roc_obj, col = "blue")
auc(roc_obj)
- 혼동행렬 결과는 다음과 같았습니다:

- 정확도: 72.7% (정확히 예측한 비율이었습니다)
- 재현율(Recall): 66.6% (실제 질환자 중 예측 성공 비율이었습니다)
- 정밀도(Precision): 75.4% (예측된 질환자 중 실제 질환자 비율이었습니다)
- AUC (곡선면적): 0.791 → 분류 성능이 우수했습니다
결론 및 시사점
- 수축기 혈압은 심혈관 질환 위험 예측에서 핵심 변수였으며,
1단위 증가 시 위험이 6% 증가하는 것으로 나타났습니다.
- 콜레스테롤 수치가 높을수록 질환 위험이 65% 증가하여, 가장 강력한 위험 요인 중 하나로 확인되었습니다.
- 나이와 BMI 역시 질환 위험을 높이는 유의한 요인이었습니다.
- 반면, 운동 여부는 OR = 0.794로 위험을 약 21% 낮추는 보호 요인으로 작용했습니다.
- 일부 변수(흡연, 음주, 혈당)는 기대와 반대되는 방향성을 보이며
- 민감도(66.6%)가 정밀도(75.4%)보다 낮기 때문에, 실제 질환자를 일부 놓칠 수 있다는 점에서
임상적 응용 시 주의가 필요합니다.
심혈관 질환 데이터셋 다운로드
R코드 다운로드
'IT관련' 카테고리의 다른 글
| R로 분석한 미국 범죄 데이터 (USArrests) (1) | 2025.05.14 |
|---|---|
| 데이터마이닝(Data Mining)이란? (3) | 2025.05.14 |
| 메타 점수가 높은 게임들의 공통점은? ( 캐글 데이터로 보는 게임 공식 ) (0) | 2025.04.30 |
| 직장인을 위한 ChatGPT 꿀팁( + ChatGPT 프롬프트 50선 다운로드) (0) | 2025.04.28 |
| 영화 흥행 분석 프로젝트( Kaggle 영화 데이터셋 ) (0) | 2025.04.26 |



