데이터 분석을 하다 보면 "정확한 모델인가?", "과적합된 건 아닐까?"라는 고민이 들곤 합니다.
이번에는 R의 대표적인 머신러닝 패키지인 caret을 활용해, 랜덤포레스트(Random Forest) 모델을 학습하고, 5-Fold 교차검증으로 모델 성능을 평가해보는 과정을 소개합니다.
🧑🏫 사용 데이터: iris
iris 데이터셋은 머신러닝 입문자들에게 가장 많이 사용되는 데이터입니다.
- 총 150개 샘플
- 4개의 독립 변수 (꽃잎 길이/너비, 꽃받침 길이/너비)
- 3개의 품종 분류 (setosa, versicolor, virginica)
🛠️ 분석 과정 요약
- caret 패키지 설치 및 로드
- trainControl()을 이용한 5-Fold 교차검증 설정
- train() 함수로 랜덤포레스트 모델 훈련
- 최적의 하이퍼파라미터 mtry 자동 선택
- 모델 정확도 및 분류 성능 평가
# 패키지 설치
install.packages("caret") # 처음 한 번만 설치
library(caret)
# 데이터 불러오기
data(iris)
str(iris)

# 5-Fold 교차검증 설정
control <- trainControl(method = "cv", number = 5)
# 모델 훈련(rondomforest) - Random Forest
model <- train(Species ~ ., data = iris, method = "rf", trControl = control)
# 결과 출력
print(model)
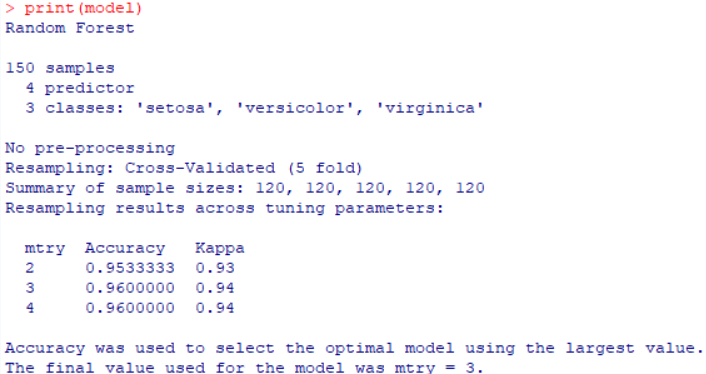
📊 2. 모델 출력 해석하기
Random Forest
150 samples
4 predictor
3 classes: 'setosa', 'versicolor', 'virginica'
Resampling: Cross-Validated (5 fold)
Summary of sample sizes: 120, 120, 120, 120, 120
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.9400000 0.91
3 0.9533333 0.93
4 0.9533333 0.93
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was mtry = 3.
용어설명
| mtry | 각 트리에서 노드를 분할할 때 고려할 변수의 수 |
| Accuracy | 예측 정확도 (전체 예측 중 정답 비율) |
| Kappa | 분류의 일치도를 측정하는 지표 (0~1 사이, 1에 가까울수록 완벽) |
🔍 해석
- 모델은 다양한 mtry 값(2, 3, 4)을 시도해본 결과, mtry = 3일 때 가장 높은 성능(정확도 95.33%)을 보였습니다.
- Kappa = 0.93도 매우 우수한 수치로, 모델이 각 품종을 정확하게 분류하고 있다는 의미입니다.
- 최종적으로 mtry = 3을 선택한 모델이 저장됩니다.
❓ 교차검증(Cross Validation)은 왜 할까?
- 단 한 번의 훈련/테스트 분할은 편향될 수 있습니다.
- 5-Fold 교차검증은 데이터를 5개로 나눠 5번 훈련과 평가를 반복하고, 평균 성능으로 모델을 평가합니다.
- 결과적으로 더 신뢰할 수 있는 모델 평가가 가능합니다.
✅ 결론 정리
| 최적 mtry 값 | 3 |
| 최고 정확도 | 95.33% |
| 최고 Kappa | 0.93 |
| 모델 안정성 | 매우 우수 (고정된 데이터에도 견고한 성능) |
💡 모델 시각화
plot(model)

🔍 축 설명
- x축: #Randomly Selected Predictors
→ 즉, mtry 값.
→ 트리 분할 시 고려할 무작위로 선택된 예측 변수 개수 - y축: Accuracy (Cross-Validation)
→ 5-Fold 교차검증을 통해 얻은 평균 예측 정확도
📈 그래프 읽기
| mtry 값 | 교차검증 정확도 |
| 2 | 약 0.953 |
| 3 | 약 0.960 |
| 4 | 약 0.960 |
- mtry = 3과 mtry = 4에서 정확도 최고치 (약 96.0%)
- 하지만 일반적으로 caret은 더 간단한 모델을 선호하므로 mtry = 3이 최적값으로 선택됩니다.
- mtry = 2일 경우 정확도가 상대적으로 낮은 것으로 나타남 (약 95.3%)
- 이 그래프는 랜덤 포레스트 모델이 다양한 mtry 값에 대해 어떤 성능(정확도)을 보였는지 시각적으로 보여줍니다.
- 정확도는 mtry = 3에서 최고치를 달성했으며, 이 값이 최적의 하이퍼파라미터로 자동 선택됩니다.
- 모델 튜닝 결과를 직관적으로 확인할 수 있어서, 사용자 입장에서 설명하거나 리포트를 작성할 때 매우 유용합니다.
🏁 마무리
caret 패키지는 R에서 모델 학습과 검증을 매우 간단하고 강력하게 해주는 도구입니다.
단순한 분류를 넘어, 데이터 과학자처럼 교차검증으로 모델을 평가하는 방법에 대한 이야기를 다루었습니다.
2025.05.16 - [IT관련] - 미국 50개 주의 문맹률, 소득, 교육수준의 상관관계는?
미국 50개 주의 문맹률, 소득, 교육수준의 상관관계는?
R 내장 데이터셋 state.x77로 알아보는 기초 데이터 분석데이터 분석을 배우기 시작하면 누구나 한 번쯤 마주하게 되는 것이 바로 R의 내장 데이터셋입니다. 그중 오늘은 미국 50개 주의 사회경제
aostory.co.kr
2025.05.14 - [IT관련] - R로 분석한 미국 범죄 데이터 (USArrests)
R로 분석한 미국 범죄 데이터 (USArrests)
“도시화가 범죄를 유발한다”는 말, 들어본 적 있으신가요?이번 글에서는 R 내장 데이터셋인 USArrests를 활용하여,미국 각 주(State)의 도시화율(UrbanPop)과 범죄율 사이의 상관관계를 분석해보겠습
aostory.co.kr
2025.04.30 - [IT관련] - 메타 점수가 높은 게임들의 공통점은? ( 캐글 데이터로 보는 게임 공식 )
메타 점수가 높은 게임들의 공통점은? ( 캐글 데이터로 보는 게임 공식 )
메타 점수가 높은 게임들의 공통점은?( 캐글 데이터로 보는 게임 공식 ) [ 목차 ] 사용한 데이터 분석목표 R 코드: 데이터 로딩 및 전처리 시각화 분석 - 장르별 메타 점수 분포 - 플랫폼별 메타 점
aostory.co.kr
'IT관련' 카테고리의 다른 글
| R로 배우는 데이터 분석: 데이터 분할과 시각화 (3) | 2025.05.19 |
|---|---|
| 미국 50개 주의 문맹률, 소득, 교육수준의 상관관계는? (3) | 2025.05.16 |
| 데이터 쉐어링 완전 정복! (4) | 2025.05.16 |
| R로 분석한 미국 범죄 데이터 (USArrests) (1) | 2025.05.14 |
| 데이터마이닝(Data Mining)이란? (3) | 2025.05.14 |



