데이터 분석에서 가장 중요한 과정 중 하나는 데이터 분할(Data Splitting)입니다. 좋은 모델을 만들기 위해선 단순히 정확도가 높은 것보다 일반화 성능, 즉 새로운 데이터를 잘 예측하는 능력이 중요합니다.
R을 활용하여 데이터를 훈련/테스트로 나누고, 간단한 모델링과 시각화를 통해 성능을 확인해보겠습니다.
1️⃣ 실습 데이터: 꽃의 품종을 분류하는 iris
iris 데이터셋은 머신러닝 입문에서 자주 사용되는 예제로,
세 가지 품종의 붓꽃(Species)을 4가지 특성(Sepal, Petal 길이/너비)으로 구분합니다.
# 데이터 불러오기
data(iris)
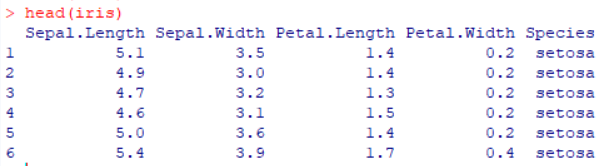
head(iris)
2️⃣ Hold-out 방식으로 데이터 분할 ( 7 : 3 )
Hold-out 방식은 데이터를 한 번 나누고, 훈련용 데이터로 모델을 학습한 뒤 테스트 데이터로 성능을 평가하는 가장 간단한 방법입니다.
set.seed(123) # 재현성을 위한 시드 고정
# 데이터 인덱스 무작위로 추출 (70%)
index <- sample(1:nrow(iris), size = 0.7 * nrow(iris))
# 훈련/테스트 데이터 분할
train_data <- iris[index, ]
test_data <- iris[-index, ]
# 데이터 크기 확인
cat("훈련 데이터 수:", nrow(train_data), "\n")
cat("테스트 데이터 수:", nrow(test_data), "\n")

3️⃣ 훈련 데이터 시각화: 품종별 분포 확인
ggplot2 패키지를 이용해 훈련 데이터에서 품종별 분포를 시각화해 봅니다.
library(ggplot2)
ggplot(train_data, aes(x = Petal.Length, y = Petal.Width, color = Species)) +
geom_point(size = 3, alpha = 0.8) +
labs(title = "훈련 데이터의 꽃잎 특성 분포", x = "Petal Length", y = "Petal Width") +
theme_minimal()
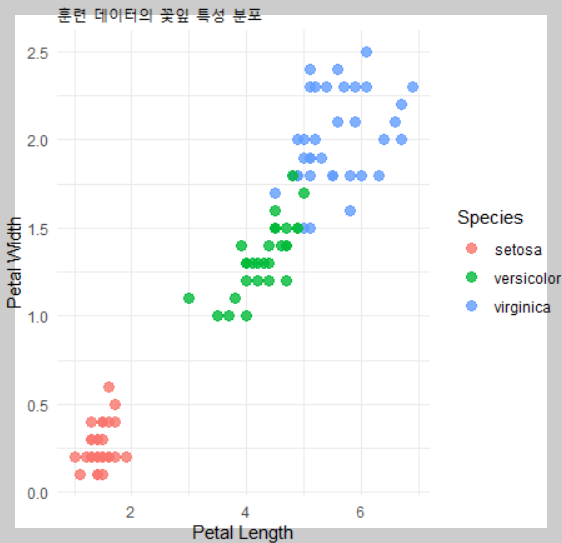
📌 시각화 해석
- setosa는 명확하게 versicolor와 virginica와 구분됩니다.
- versicolor와 virginica는 다소 겹치는 부분이 있어 분류가 어려울 수 있습니다.
4️⃣ 모델 학습: 랜덤 포레스트(Random Forest)
library(randomForest)
# 랜덤 포레스트 모델 학습
set.seed(123)
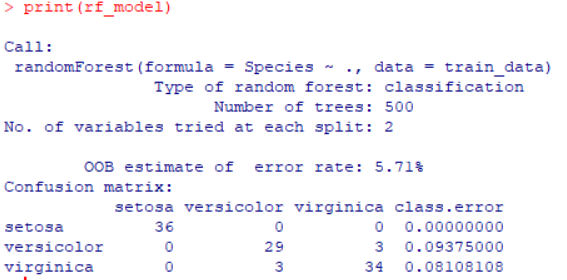
rf_model <- randomForest(Species ~ ., data = train_data)
# 훈련 결과 출력
print(rf_model)
5️⃣ 테스트 데이터로 예측 및 성능 평가
# 테스트 데이터에 대해 예측
pred <- predict(rf_model, newdata = test_data)
# 혼동 행렬로 정확도 확인
library(caret)
confusionMatrix(pred, test_data$Species)

📌 혼동행렬 해석
- 정확하게 예측된 값은 대각선에 위치합니다:
- setosa: 14개 중 14개 정확히 예측 (100%)
- versicolor: 17개 중 17개 정확히 예측 (100%)
- virginica: 14개 중 13개 정확히 예측 (1개를 versicolor로 잘못 예측)
✅ 대부분의 데이터를 정확히 분류했으며, virginica 1개만 오분류됨.
📊 Overall Statistics
- Accuracy (정확도): 0.9778
전체 테스트 데이터 중 약 97.8%를 정확히 예측했음. - 95% CI (신뢰구간): (0.8823, 0.9994)
정확도는 약 88%~99.9% 범위 내에 있을 확률이 높음. - No Information Rate (NIR): 0.4
가장 많은 클래스만 무조건 예측했을 때 얻을 수 있는 정확도 (여기선 versicolor가 가장 많음). - P-Value [Acc > NIR] < 2.2e-16
모델의 정확도가 NIR보다 유의하게 높다는 것을 의미 (즉, 성능이 의미 있음). - Kappa: 0.9664
범주형 분류의 일치도 지표. 1에 가까울수록 좋음 (0.8 이상이면 아주 훌륭함).
✅ 종합 평가
| Accuracy | 97.8% | 매우 높은 전체 정확도 |
| Kappa | 0.966 | 강한 일치도 |
| 민감도/정밀도 | 모두 우수 | 클래스 별 균형잡힌 성능 |
| 오분류 | virginica 1건 | 큰 문제 없음 |
이 모델은 iris 데이터셋에 대해 거의 완벽에 가까운 분류 성능을 보여주며, 실전 프로젝트의 기본 모델로 매우 적합합니다.
2025.04.26 - [IT관련] - 영화 흥행 분석 프로젝트( Kaggle 영화 데이터셋 )
영화 흥행 분석 프로젝트( Kaggle 영화 데이터셋 )
🎥 "영화가 성공하려면 무엇이 필요할까?"여러분은 영화가 히트하는 데 무엇이 가장 중요한 요소라고 생각하시나요?막대한 제작비? 유명 배우? 아니면 뛰어난 감독?이런 궁금증을 데이터로 풀
aostory.co.kr
2025.04.24 - [IT관련] - R로 배우는 회귀분석 실습 ( 베이징 미세먼지(PM2.5) 데이터 분석 )
R로 배우는 회귀분석 실습 ( 베이징 미세먼지(PM2.5) 데이터 분석 )
R로 배우는 회귀분석 실습 ( 베이징 미세먼지(PM2.5) ) [ 목차 ] 분석목적 데이터개요 분석방법 R코드 - 데이터 불러오기 - 변수 추출 및 전처리 - 다중회귀 모델 생성 및 결과 요약 - 시각화 결론 및
aostory.co.kr
2025.04.09 - [IT관련] - 수면 시간과 스트레스가 수면의 질에 어떤 영향을 줄까? ( + R 회귀분석 )
수면 시간과 스트레스가 수면의 질에 어떤 영향을 줄까? ( + R 회귀분석 )
수면 시간과 스트레스가 수면의 질에 어떤 영향을 줄까? [ 목차 ] 프로젝트 개요 사용한 데이터 R코드 분석 분석 결과 요약 시사점 및 마무리 1. 프로젝트
aostory.co.kr
'IT관련' 카테고리의 다른 글
| R로 배우는 랜덤포레스트 교차검증 모델 – caret 패키지 실습 (3) | 2025.05.19 |
|---|---|
| 미국 50개 주의 문맹률, 소득, 교육수준의 상관관계는? (3) | 2025.05.16 |
| 데이터 쉐어링 완전 정복! (4) | 2025.05.16 |
| R로 분석한 미국 범죄 데이터 (USArrests) (1) | 2025.05.14 |
| 데이터마이닝(Data Mining)이란? (3) | 2025.05.14 |



